HiPERiSM - High Performance Algorism Consulting
HCTR-2011-4: Cost-benefit Comparison for AMDÛ and IntelÛ processors
COST-BENEFIT COMPARISON FOR AMDÛ AND IntelÛ PROCESSORS
George Delic
HiPERiSM Consulting, LLC.
1.0 CHOICE OF BENCHMARK
1.1 Community Multiscale Air Quality (CMAQ) model
This report presents results of porting the latest multithreaded version of the Community Multiscale Air Quality (CMAQ) model, CMAQ 4.7.1, developed by HiPERiSM Consulting to recent multi-core and many-core processors. The purpose in this exercise, is to evaluate the cost versus benefit of these processors for CMAQ workloads. HiPERiSM has produced a series of reports (HCTR-2010-1, HCTR-2010-2, HCTR-2010-3, HCTR-2010-5, HCTR-2010-6) detailing studies of performance for both serial and multithread parallel versions of CMAQ. Numerous results have been reported in conference presentations at the Annual CMAS meetings (http://www.cmascenter.org) and the multithreaded version has been submitted to the U.S. EPA for inclusion in future releases. The platforms chosen are those described in the preceding reports (HCTR-2011-1, HCTR-2011-2, HCTR-2011-3). In the hybrid OpenMP+MPI version of CMAQ used here, only a single MPI process is used with multiple OpenMP threads and a fixed parallel work scheduling algorithm.
1.2 Hardware test bed
The hardware platforms are the 2-processor (2P) Intel W5590 quad core and 4-processor (4P) Advanced Micro Devices (AMD) 6176SE 12 core CPUs, as described in Table 1.1 of a preceding report (HCTR-2011-1). Of interest here is to compare the cost-benefit and workload throughput on these multi-core CPUs on a single mother board sharing a bus architecture.
1.3 Hardware cost
The costs reported here are the actual real-world costs experienced at HiPERiSM Consulting, LLC, where both AMD and Intel nodes were integrated from a list of parts purchased separately from multiple vendors. A summary is shown in Table 1.1 where costs are for the years shown. The hardware cost per core for the Intel solution is 3.7 times that of the AMD processor. Although the AMD platform discussed here is a 4P node, the cost differential for a 2P solution with either AMD or Intel CPUs is not great. However, with 3 times more cores in the AMD case there is more scope for workload through-put.
Table 1.1. Essential features and costs for processors discussed in this report.
|
Vendor |
CPU |
Model |
GHz |
Cores |
Watts |
Watts per core |
Cost per CPU |
Cost per core |
|
AMD |
Opteron |
6176SE |
2.3 |
12 |
105 |
8.75 |
$1371 (2010) |
$114 |
|
Intel |
Nehalem |
W5590 |
3.3 |
4 |
130 |
32.5 |
$1690 (2009) |
$423 |
1.4 Hardware energy consumption
Comparing power consumption between AMD and Intel processors in Table 1.1shows that the power consumption per core is 3.7 times greater for the Nehalem processor. However, in both cases, power consumption does vary with load. Because of the package density, a 4P solution usually includes ample forced air cooling which precludes desk-side solutions because of the noise factor.
2.0 COMPILING THE BENCHMARK
To compile the HiPERiSM's hybrid OpenMP + MPI CMAQ 4.7.1 model the Intel 11.0 compiler was used. All compilations used the highest level of optimizations available for the respective hosts with "safe math" options as described in the HiPERiSM 2010 Annual CMAS meeting (http://www.cmascenter.org) . The MPICH mpirun command was used with the -all-local switch to contain executions on-node. For on-node bandwidth benchmarks see report HCTR-2011-1.
3.0 BENCHMARK RESULTS
3.1 Wall clock times
Wall clock times for CMAQ 4.7.1 have been measured for the case of the Intel compiler and results are shown in Tables 3.1 and 3.2, respectively. In Table 3.1 each run was executed in dedicated mode (i.e. no concurrent run executions) on both platforms and in this case the number of cores utilized is the same as the number of threads allocated in parallel thread teams. The last two columns of Table 3.1 show the ratio of wall clock times for each run on AMD and Intel platforms. It is clear that for individual runs the Intel Nehalem quad core CPU has more than two times the through-put of the AMD 12 core Opteron CPU for the same core count on each.
Table 3.1. Individual CMAQ 4.7.1 runs on Intel and AMD nodes showing the wall clock time for four separate runs in three groups corresponding to a choice of 2,4, or 8 threads per run.
|
Run number |
Number of threads per run |
----------- Intel ---------- |
---------- AMD ---------- |
Ratio = AMD/Intel |
Ratio = Intel/AMD |
||
|
Wall clock (hours) |
Cores utilized |
Wall clock (hours) |
Cores utilized |
||||
|
1 |
2 |
26.07 |
2 |
56.58 |
2 |
2.17 |
0.46 |
|
2 |
2 |
25.74 |
2 |
56.52 |
2 |
2.20 |
0.46 |
|
3 |
2 |
25.67 |
2 |
57.32 |
2 |
2.23 |
0.45 |
|
4 |
2 |
25.70 |
2 |
56.85 |
2 |
2.21 |
0.45 |
|
5 |
4 |
22.32 |
4 |
47.85 |
4 |
2.14 |
0.47 |
|
6 |
4 |
22.26 |
4 |
47.86 |
4 |
2.15 |
0.47 |
|
7 |
4 |
22.09 |
4 |
48.21 |
4 |
2.18 |
0.46 |
|
8 |
4 |
22.15 |
4 |
48.61 |
4 |
2.19 |
0.46 |
|
9 |
8 |
20.15 |
8 |
42.82 |
8 |
2.13 |
0.47 |
|
10 |
8 |
19.93 |
8 |
42.12 |
8 |
2.11 |
0.47 |
|
11 |
8 |
20.18 |
8 |
42.81 |
8 |
2.12 |
0.47 |
|
12 |
8 |
20.01 |
8 |
42.56 |
8 |
2.13 |
0.47 |
However, the situation changed for composite workloads that have enhanced scope for concurrency on the AMD Opteron platform. The results for workload completion times are shown in Table 3.2 where for each row the number of cores utilized is the sum of all thread counts in concurrent runs. From Table 3.1 the thread count per run is 2 (runs 1-4), 4 (runs 5-8), and 8 (runs 9-12), respectively. For the AMD platform all run numbers in a given row of Table 3.2 constitute a workload and all execute concurrently. For the Intel platform the core count is limited to a maximum of 8 and the notation + is used to indicate that the adjacent numbered runs are concatenated (i.e. execute sequentially). The last two columns show the ratio of wall clock times for each workload on AMD and Intel platforms. From Table 3.2 it is clear that for workloads that are composites of individual runs, the AMD 12 core Opteron CPU has superior workload throughput when compared with the Intel Nehalem quad core CPU. As concurrency increases the AMD platform attains as much as 1.4 to 1.9 more workload throughput compared to the Intel node. This would be the case even for two processor (2P) configurations of both platforms (8 Intel cores versus 24 AMD cores).
Table 3.2. Each row of this table shows a composite CMAQ 4.7.1 workload on Intel and AMD nodes. The wall clock time is for completion of the entire workload constituted from the corresponding combination of numbered runs from Table 3.1.
|
Workload by run numbers |
Number of threads per run |
---------- Intel --------- |
-------- AMD ---------- |
Ratio = AMD/Intel |
Ratio = Intel/AMD |
||
|
Wall clock (hours) |
Cores utilized |
Wall clock (hours) |
Cores utilized |
||||
|
1+2, 3+ 4 |
2 |
51.81 |
4 |
57.32 |
8 |
1.11 |
0.90 |
|
5+6,7+8 |
4 |
44.58 |
8 |
48.61 |
16 |
1.09 |
0.92 |
|
9+10 |
8 |
40.08 |
8 |
42.82 |
16 |
1.07 |
0.94 |
|
11+12 |
8 |
40.20 |
8 |
42.81 |
16 |
1.07 |
0.94 |
|
9+10+11 |
8 |
60.35 |
8 |
42.81 |
24 |
0.71 |
1.41 |
|
9+10+11+12 |
8 |
80.28 |
8 |
42.81 |
32 |
0.53 |
1.88 |
3.2 Throughput scaling with core count
Fig. 3.1 is a simple view showing the completion time in hours for each of the six workloads of Table 3.2. When the AMD node uses 3 or 4 times more cores than the Intel platform for workloads 5 and 6, the time to completion is reduced by factors of 1.4 and 1.9, respectively.

Fig 3.1. This shows the completion time in hours for each of the six workloads of Table 3.2 on Intel and AMD nodes. For the respective platforms the number of cores utilized is shown as data labels for each workload.
The concurrency scaling for the six workloads in Table 3.2 may be compared as the ratio of the respective utilized cores and the corresponding ratio of the wall clock times. The first ratio is the number of cores utilized on the AMD platform versus the number used on the Intel node. The second is the corresponding ratio of wall clock times on the Intel node versus the AMD platform. Fig. 3.2 displays these two metrics as a function of the workload. The last two workloads that have the highest level of concurrency also have the greatest gain in workload through-put on the AMD platform compared to the Intel node.
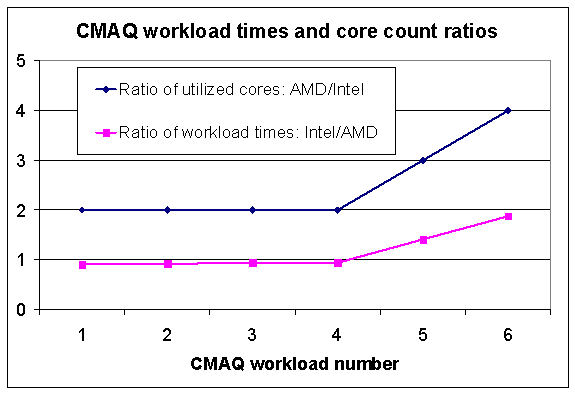
Fig 3.2. For the six workloads in respective rows of Table 3.2 two ratios are compared to demonstrate the increased workload throughput on the AMD platform as concurrency increases.
4.0 COMPARING AMD AND INTEL PROCESSORS
For a composite workload consisting of multiple CMAQ runs it is of interest to compare performance of the Intel W5590 quad core processor node against the AMD 6176SE 12 core processor. For this purpose the the problem size and compiler options were identical, but the runs differed in the choice of the thread team size and number of cores utilized. Once there is a sufficiently high level of concurrency in the hybrid OpenMP+MPI parallel version of CMAQ, the AMD solution offers a clear workload throughput gain over the Intel solution for composite workloads. This outcome is largely the outcome of the larger number of cores in the AMD solution for the same CPU configuration. In the case that the workload consists of a single run, with a limited thread count less than 8, then the Intel Nehalem could be the optimal choice based on the results of this stury. A 4P Intel Nehalem solution could be viewed as a less cost effective solution when compared to the AMD solution because of factors such as the cost per CPU and power demand per core.
5.0 CONCLUSIONS
With 8 cores on the Intel node the scope of this benchmark exploration showed superior performance compared the AMD node for an individual application. This is the result of a higher clock speed and superior bandwidth. However, throughput results for workloads with a high level of concurrency gained by factors of 1.4 to 1.9 over the Intel solution because of the higher core count for the AMD Opteron node. In addition the AMD solution offers better cost benefit features with lower cost per CPU and lower power consumption per core compared to the Intel Nehalem option.
![]()
![]()
HiPERiSM Consulting, LLC, (919) 484-9803 (Voice)
(919) 806-2813 (Facsimile)

